

After discussed in detail the definitions of Apache Kafka, We’ll discuss about Kafka Stream and how to implement Kafka Stream in Spring Boot with Java.
What is Kafka stream?
Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka’s server-side cluster technology.
Why use Kafka Stream?
Core Kafka Streams concepts include: topology, time, keys, windows, KStreams, KTables, domain-specific language (DSL) operations, and SerDes.
Kafka Topology
A processor topology includes one or more graphs of stream processors (nodes) connected by streams (edges) to perform stream processing. In order to transform data, a processor receives an input record, applies an operation, and produces output records.
A source processor receives records only from Kafka topics, not from other processors. A sink processor sends records to Kafka topics, and not to other processors.
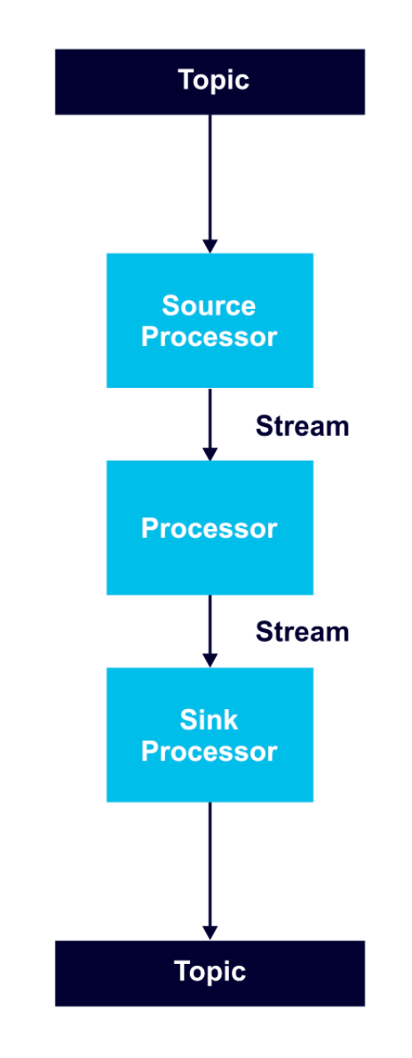
Processor nodes can run in parallel, and it is possible to run multiple multi-threaded instances of Kafka Streams applications. However, it is necessary to have enough topic partitions for the running stream tasks, since Kafka leverages partitions for scalability.
Stream tasks serve as the basic unit of parallelism, with each consuming from one Kafka partition per topic and processing records through a processor graph of processor nodes.
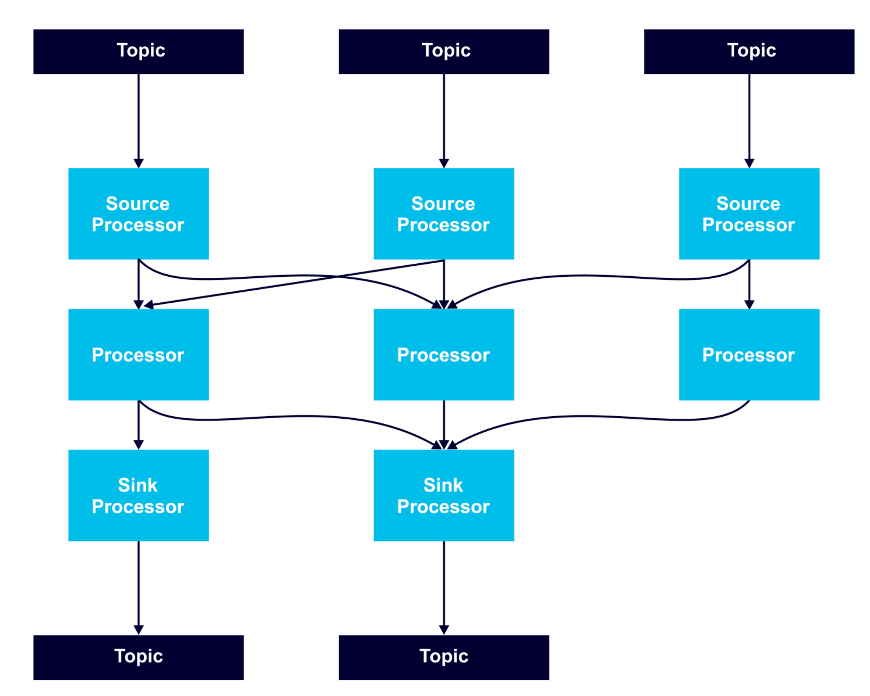
To keep partitioning predictable and all stream operations available, it is a best practice to use a record key in records that are to be processed as streams.
Time
Time is a critical concept in Kafka Streams. Streams operations that are windowing-based depend on time boundaries. Event time is the point in time when an event is generated. Processing time is the point in time when the stream processing application consumes a record. Ingestion time is the point when an event or record is stored in a topic. Kafka records include embedded time stamps and configurable time semantics.
Domain-Specific Language (DSL) built-in abstractions
The DSL is a higher level of abstraction. The methods of the DSL let you think about how you want to transform the data rather than explicitly creating a processor Topology. The Topology is built for you with the StreamsBuilder#build() method.
The Streams DSL offers streams and tables abstractions, including KStream, KTable, GlobalKTable, KGroupedStream, and KGroupedTable.
Developers can leverage the DSL as a declarative functional programming style to easily introduce stateless transformations such as map and filter operations, or stateful transformations such as aggregations, joins, and windowing.
KTables
KTable is an abstraction of a changelog stream from a primary-keyed table. Each record in this changelog stream is an update on the primary-keyed table with the record key as the primary key.
A KTable is either defined from a single Kafka topic that is consumed message by message or the result of a KTable transformation. An aggregation of a KStream also yields a KTable.
A KTable can be transformed record by record, joined with another KTable or KStream, or can be re-partitioned and aggregated into a new KTable.
Some KTables have an internal state (a ReadOnlyKeyValueStore) and are therefore queryable via the interactive queries API.
For example
final KTable table = ...
...
final KafkaStreams streams = ...;
streams.start()
...
final String queryableStoreName = table.queryableStoreName(); // returns null if KTable is not queryable
ReadOnlyKeyValueStore view = streams.store(queryableStoreName, QueryableStoreTypes.keyValueStore());
view.get(key);
DSL Operations
The following table offers a quick-and-easy reference for understanding all DSL operations and their input and output mappings, in order to create streaming applications with complex topologies:
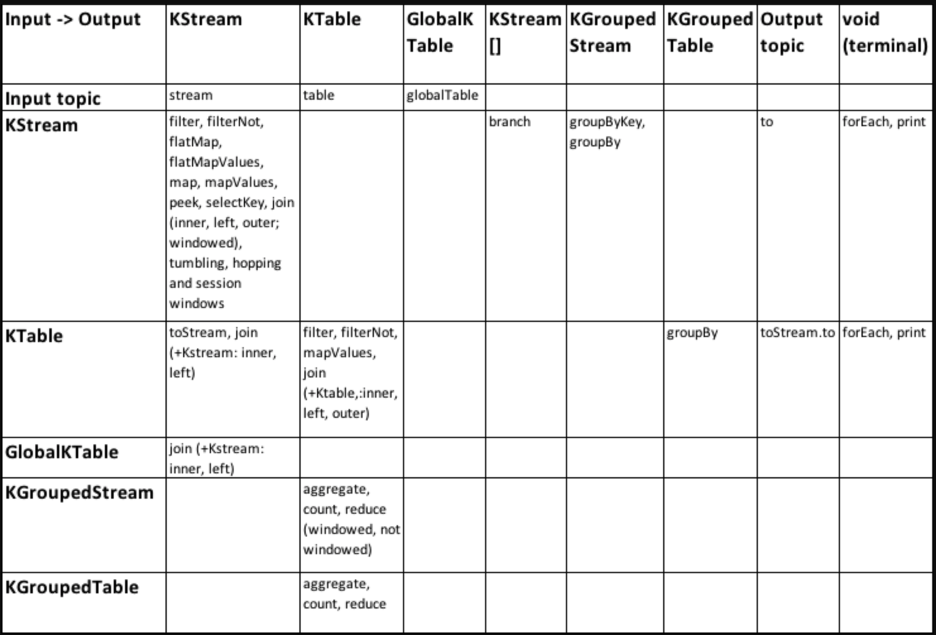
SerDes
Kafka Streams applications need to provide SerDes, or a serializer/deserializer, when data is read or written to a Kafka topic or state store. This enables record keys and values to materialize data as needed. You can also provide SerDes either by setting default SerDes in a StreamsConfig instance, or specifying explicit SerDes when calling API methods.
The following diagram displays SerDes along with other data conversion paths:
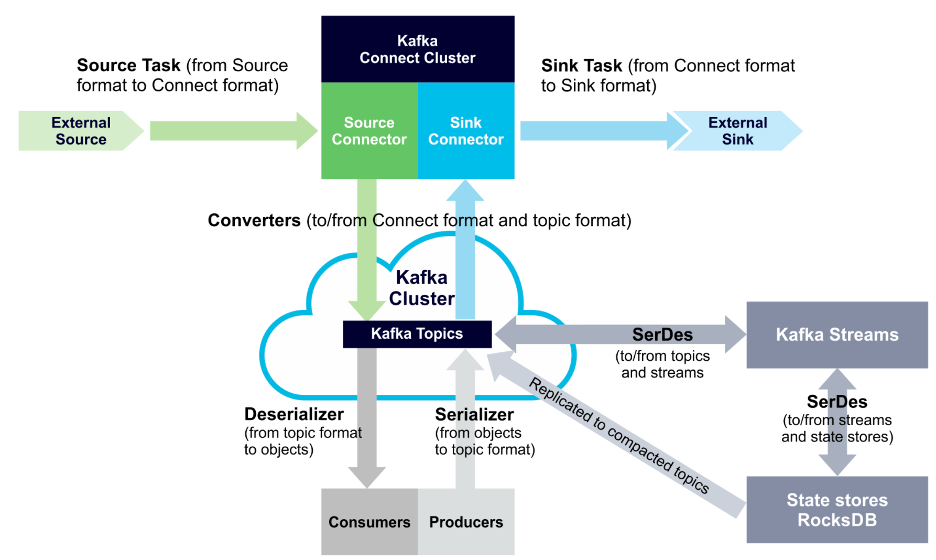
Demo Kafka stream
Below is a demo Kafka stream: build word count application.
package com.learncode24h.wordcount;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import java.util.Locale;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
/**
* Demonstrates, using the high-level KStream DSL, how to implement the WordCount program
* that computes a simple word occurrence histogram from an input text.
* <p>
* In this example, the input stream reads from a topic named "streams-plaintext-input", where the values of messages
* represent lines of text; and the histogram output is written to topic "streams-wordcount-output" where each record
* is an updated count of a single word.
* <p>
* Before running this example you must create the input topic and the output topic (e.g. via
* {@code bin/kafka-topics.sh --create ...}), and write some data to the input topic (e.g. via
* {@code bin/kafka-console-producer.sh}). Otherwise you won't see any data arriving in the output topic.
*/
public final class WordCountDemo {
public static final String INPUT_TOPIC = "streams-plaintext-input";
public static final String OUTPUT_TOPIC = "streams-wordcount-output";
static Properties getStreamsConfig(final String[] args) throws IOException {
final Properties props = new Properties();
if (args != null && args.length > 0) {
try (final FileInputStream fis = new FileInputStream(args[0])) {
props.load(fis);
}
if (args.length > 1) {
System.out.println("Warning: Some command line arguments were ignored. This demo only accepts an optional configuration file.");
}
}
props.putIfAbsent(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
props.putIfAbsent(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.putIfAbsent(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);
props.putIfAbsent(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.putIfAbsent(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.putIfAbsent(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return props;
}
static void createWordCountStream(final StreamsBuilder builder) {
final KStream<String, String> source = builder.stream(INPUT_TOPIC);
final KTable<String, Long> counts = source
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split(" ")))
.groupBy((key, value) -> value)
.count();
// need to override value serde to Long type
counts.toStream().to(OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.Long()));
}
public static void main(final String[] args) throws IOException {
final Properties props = getStreamsConfig(args);
final StreamsBuilder builder = new StreamsBuilder();
createWordCountStream(builder);
final KafkaStreams streams = new KafkaStreams(builder.build(), props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-wordcount-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (final Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
Deploy
To deploy this application we need to create input topic and output topic
# Create the input topic
./bin/kafka-topics --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
# Create the output topic
./bin/kafka-topics --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output
Create input_file.txt for producer with the following content
welcome to learncode24h.com we are learning kafka streams thanks for reading kafka streams
Lastly, we send this input data to the input topic:
cat /tmp/file-input.txt | ./bin/kafka-console-producer --broker-list localhost:9092 --topic streams-plaintext-input
We can now inspect the output of the WordCount demo application by reading from its output topic streams-wordcount-output
./bin/kafka-console-consumer --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer