
Kafka only transfers data from producer to consumer in byte format and it doesn’t have a verification data mechanism. In fact, Kafka does not even know what kind of data it is sending or receiving; whether it is a string or integer. So Kafka needs a server to stand outside and handle data verification between producers and consumers.
What is Schema Registry?
Due to the decoupled nature of Kafka. Producers and consumers do not communicate with each other directly so they can not know the data format sent and received. If consumers receive data and deserialize it in the wrong format it can cause an exception. So Kafka needs Schema Registry lives outside and talk to producers and consumers to send and retrieve schemas that describe the data models for the messages.
Kafka uses Arvo or Protocols Buffer as a platform-neutral extensible mechanism for serializing structured data.
Avro is an open-source binary data serialization format that comes from the Hadoop world and has many use cases. Avro has a schema-based system. A language-independent schema is associated with its read and write operations. Avro serializes the data into a compact binary format, which can be deserialized by any application.
Avro uses JSON format to declare the data structures. Presently, it supports languages such as Java, C, C++, C#, Python, and Ruby.
Below is an example of Avro schema definition:
{
"namespace": "io.confluent.examples.clients.basicavro",
"type": "record",
"name": "Payment",
"fields": [
{"name": "id", "type": "string"},
{"name": "amount", "type": "double"}
]
}
Here is a break-down of what this schema defines:
namespace: a fully qualified name that avoids schema naming conflictstype: an Avro data type, for example:record,enum,union,array,map, orfixedname: unique schema name in this namespacefields: one or more simple or complex data types for aÂrecord. The first field in this record is called id, and it is of type string. The second field in this record is called amount, and it is of type double.
Protocol buffers is an open source for serializing data that can be transmitted over wire or be stored in files. The Protobuf is optimized to be faster than JSON and XML by removing many responsibilities usually done by data formats and making it focus only on the ability to serialize and deserialize data as fast as possible.
The definition of the data to be serialized is written in configuration files called proto files (.proto). The proto files can be compiled to generate the code in the user’s programming language.
How does schema registry work?
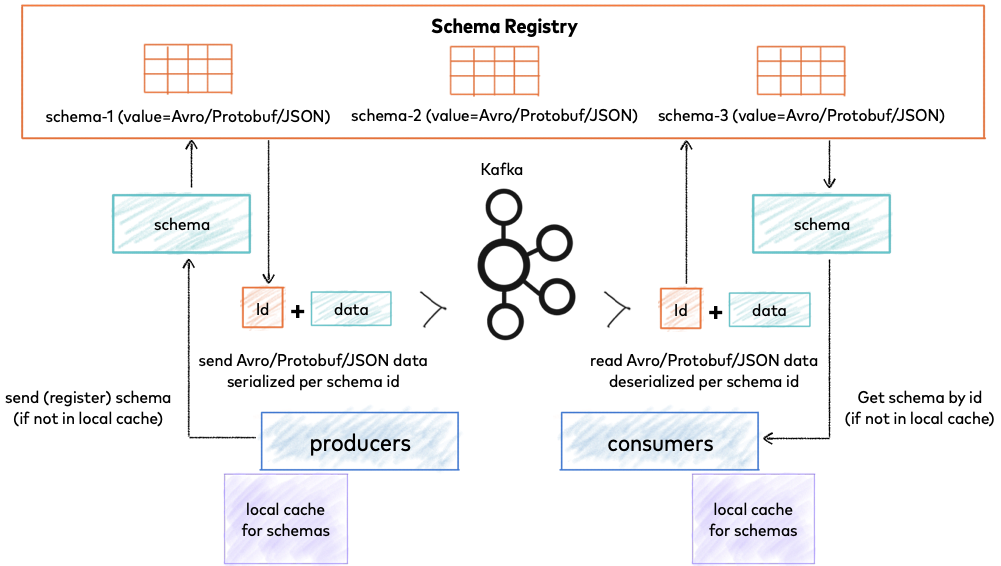
Before sending a message to brokers, producer will check schema in its local cache is present or not, if not it will send a request to Schema Registry and register the schema, Schema Registry response to producer and ID and producer will append it to the data message then send it to topic.
Consumer after received message from topic will extract ID and check Schema Registry ID has existed in its local cache. Without it, the consumer will request to Schema Registry to get schema then extract data from the message and deserialize with received schema.


Comments are closed.