
Apache Kafka was originally developed by LinkedIn, and was subsequently open-sourced in early 2011. Kafka gained the full Apache Software Foundation project status in October 2012. Kafka was born out of a need to track and process large volumes of site events, such as page views and user actions, as well as for the aggregation log data. In this tutorial we’ll discover what is Kafka? and most popular definitions in Kafka
Who is using Kafka?
- Twitter use Kafka for its mobile application performance management and analytics product, which has been clocked at five billion sessions per day in February 2015. Twitter processes this stream using a combination of Apache Storm, Hadoop, and AWS Elastic MapReduce.
- Netflix uses Kafka as the messaging backbone for its Keystone pipeline — a unified event publishing, collection, and routing infrastructure for both batch and stream processing. As of 2016, Keystone comprises over 4,000 brokers deployed entirely in the Cloud, which collectively handle more than 700 billion events per day.
- Tumblr relies on Kafka as an integral part of its event processing pipeline, capturing up 500 million page views a day back in 2012.
- Square uses Kafka as the underlying bus to facilitate stream processing, website activity tracking, metrics collection and monitoring, log aggregation, real-time analytics, and complex event processing.
- Pinterest employs Kafka for its real-time advertising platform, with 100 clusters comprising over 2,000 brokers deployed in AWS. Pinterest is turning over in excess of 800 billion events per day, peaking at 15 million per second.
- Uber is among the most prominent of Kafka adopters, processing in excess of a trillion events per day is mostly for data ingestion, event stream processing, database changelogs, log aggregation, and general-purpose publish-subscribe message exchanges.
Kafka architecture
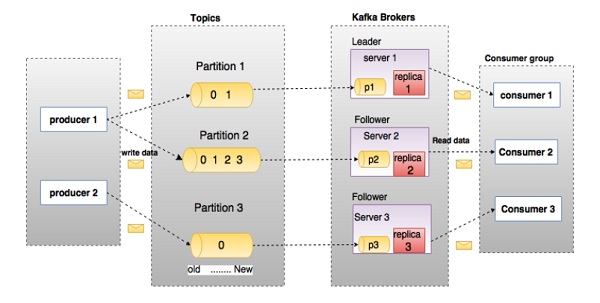
Kafka is a public/subscribe system based on event data with the participation of 4 actors: producers, consumers, brokers and zookeepers.
- Broker nodes: Responsible for the bulk of I/O operations and durable persistence within the cluster. A Kafka broker receives messages from producers and stores them on disk by specific partition and keyed by unique offset. Kafka broker allows consumers to fetch messages by topic, partition and offset. Kafka brokers can create a Kafka cluster by sharing information between each other directly or indirectly using Zookeeper.
- ZooKeeper nodes: Under the hood, Kafka needs a way of managing the overall controller status within the cluster. ZooKeeper is primarily used to track the status of nodes in the Kafka cluster and maintain a list of Kafka topics and messages.
- Producers: Kafka producers handle sending message to brokers by topic
- Consumers: Client applications that read from topics.
In the above diagram, a topic is configured into three partitions. Partition 1 has two offset with index are 0 and 1. Partition 2 has four offset with index are 0, 1, 2, and 3. Partition 3 has one offset with index equal 0. The replica is a clone of each partition with same id and offset.
Assume, if the replication factor of the topic is set to 3, then Kafka will create 3 identical replicas of each partition and place them in the cluster to make available for all its operations. In the above picture replication factor is 1 (1 partition only have 1 clone version). To balance a load in cluster, each broker stores one or more of those partitions. Multiple producers and consumers can publish and retrieve messages at the same time.
Kafka component concepts
Broker nodes
Broker acts an man in the middle help transport data between producer and consumer. Broker persits data to partitions and guarantees data can be extended over a period of time and canvas scenarios that involve component failure.
A broker is one of the units of scalability in Kafka, by increasing the number of brokers, one can achieve improved I/O, availability, and durability characteristics. A broker’s able to coordinate with the other message brokers as well as talking to ZooKeeper. Usually each server is a broker, certaintly you can also create multiple broker on a server but it isn’t recommended.
Topic
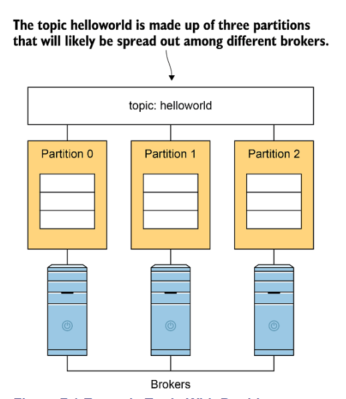
Kafka Topic is a place recevive message from producers. Topics are split into partitions. For each topic, Kafka keeps a mini-mum of one partition. Each such partition contains messages in an immutable ordered sequence. A partition is implemented as a set of segment files of equal sizes. So we can imagine a topic is a logical aggregation of partitions. Split topic to multiple partitions help Kafka can process records parallel.
When a producer publish a record, producer automatically select a partition on the basis of a record’s key. A producer will digest the byte content of the key using a hash function (Kafka uses murmur2 for this purpose). The highest-order bit of the hash value is masked off to force it to a positive integer, before taking the result, modulo the number of partitions, to arrive at the final partition number. Same record when saving Kafka will select same partition but if you change the number of partitions, hash value of record will be changed and Kafka can select another partition when saving record. The contents of the topic and the producer’s interactions with the topic are depicted below.
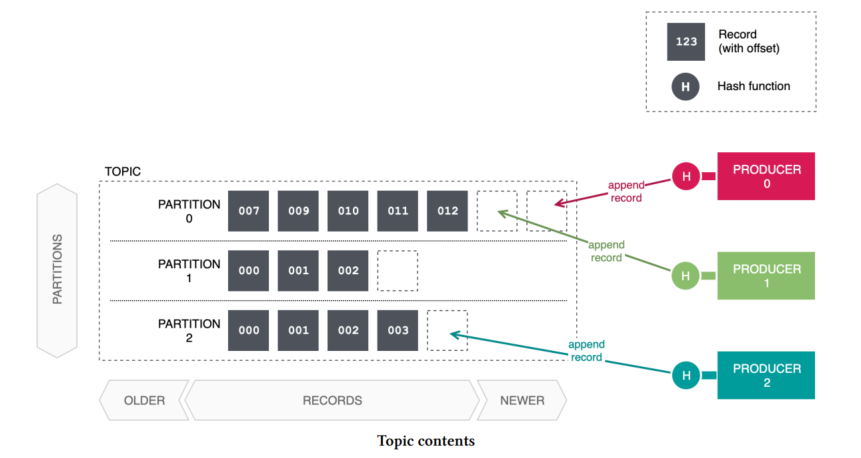
Such is the nature of hashing, a records with different hashes may also end up in the same partition due to hash collisions.
Consumer groups and load balancing
Kafka’s producer-topic-consumer topology adheres to a flexible and highly generalised multipoint-to-multipoint model, meaning that there may be any number of producers and consumers simultaneously interacting with a topic.
A consumer is a process or thread that attaches to a Kafka cluster via a client library. When multiple consumers are subscribed to a topic and belong to the same consumer group, each consumer in the group will receive messages from a different subset of the partitions in the topic.
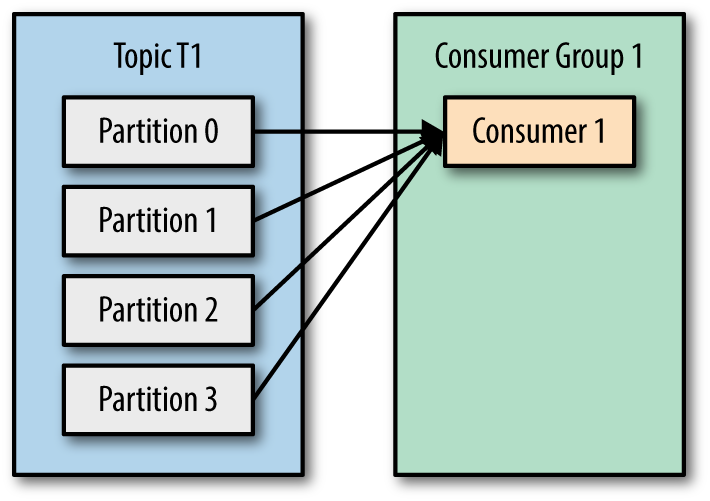
Let’s take topic T1 with four partitions. Now suppose we created a new consumer C1, which is the only consumer in group G1, and use it to subscribe to topic T1. Consumer C1 will get all messages from all four T1 partitions.
If we add another consumer C2, to group G1, each consumer will only get messages from two partitions. For example: messages from partition 0 and 2 consumed by C1 and messages from partitions 1 and 3 consumed by consumer C2.
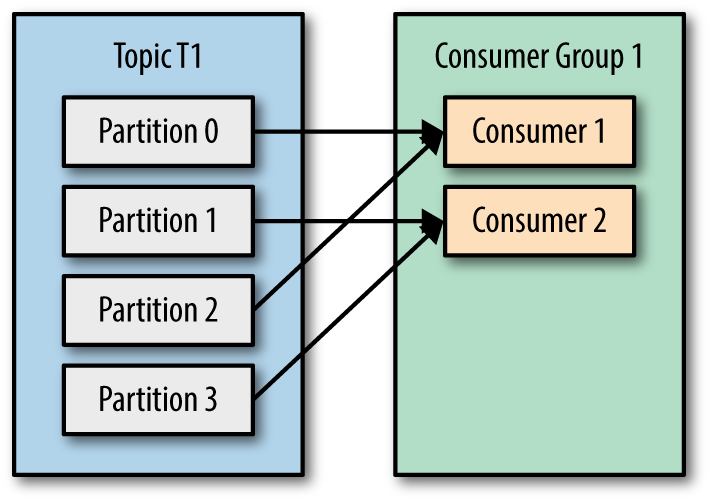
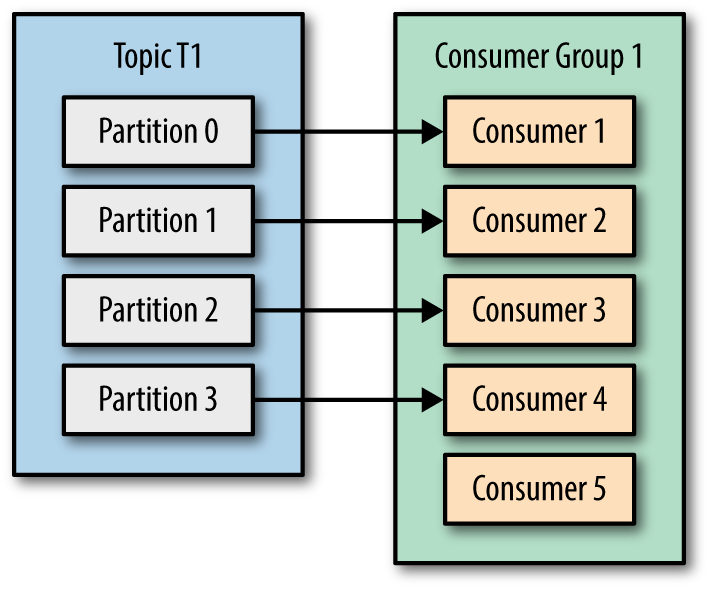
If we add more consumers to a single group G1 subscribe single topic, and number of consumers is more than number of partitions, some of the consumers will be idle and get no messages at all because Kafka ensures that a partition may only be assigned to at most one consumer within its consumer group.
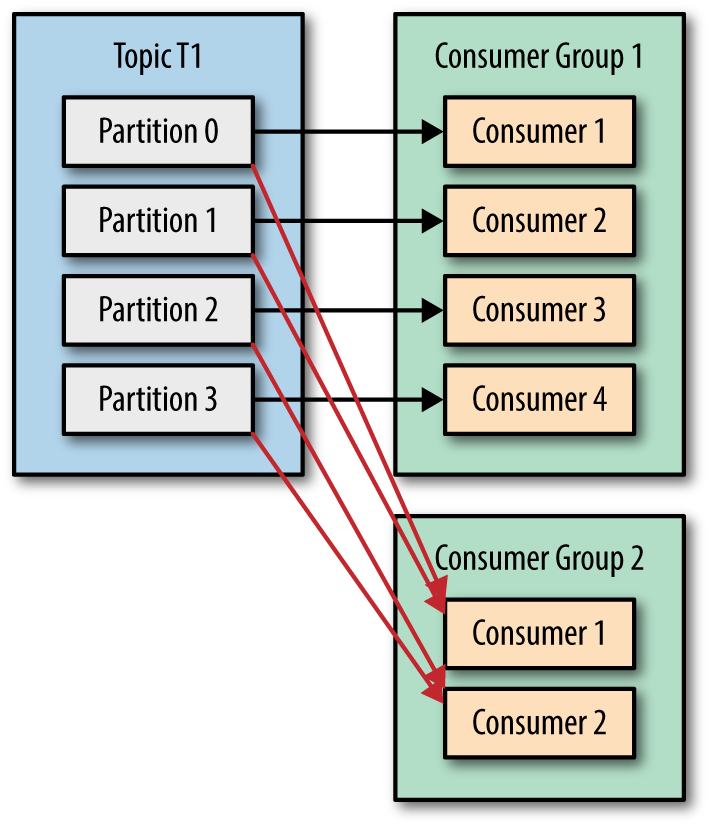
if we add a new consumer group G2 with a single consumer, this consumer will get all the messages in topic T1 independent of what G1 is doing. G2 can have more than a single consumer, in which case they will each get a subset of partitions, just like we showed for G1, but G2 as a whole will still get all the messages regardless of other consumer groups. Multiple consumer groups can subscribe same topics because:
- Offsets are “managed” by the consumers, but “stored” in a special __consumer_offsets topic on the Kafka brokers.
- Offsets are stored for each
(consumer group, topic, partition)tuple. This combination is also used as the key when publishing offsets to the __consumer_offsets topic so that log compaction can delete old unneeded offset commit messages and so that all offsets for the same(consumer group, topic, partition)tuple are stored in the same partition of the __consumer_offsets topic (which defaults to 50 partitions)


Comments are closed.