
In Apache Kafka , producer and consumer performance are very similar in that both are concerned with throughput.
Consumer Lag
For producers, we care mostly about how fast the producer is sending messages to the broker. Obviously, the higher the throughput, the better.
For consumers, we are also concerned with performance, or how fast we can read messages from a broker. But there is another way to measure consumer performance: consumer lag. The difference between how fast the producers place records on the broker and when consumers read those messages is called consumer lag.
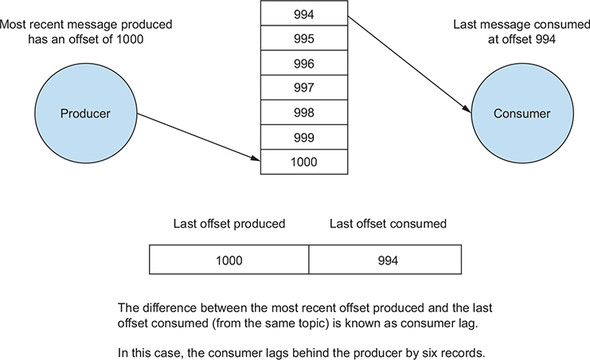
Monitor Consumer Lag
To check for consumer lag, Kafka provides a convenient command-line tool, kafka-consumer-groups.sh, found in the <kafka-install-dir>/bin directory. The script has a few options, but here we focus on the list and describe options. These two options will give you the information you need about consumer group performance.
The kafka-consumer-groups tool can be used to list all consumer groups, describe a consumer group, delete consumer group info, or reset consumer group offsets.
Use the following command to describe offsets committed to Kafka:
kafka-consumer-groups.bat --bootstrap-server 127.0.0.1:9092 --describe --group first_app
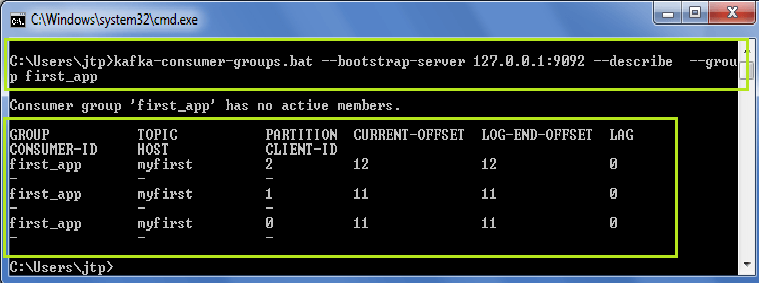
Lag value is 0 -indicates that the consumer has read all the data: 12 messages sent – 12 message read = 0 lag (or records behind), similar for other consumers.
Kafka ACKS and ISR (In-Sync Replicas)
Those two configs are acks and min.insync.replicas have a big impact on performance of Kafka. So in this tutorial we’ll dig deep about them.
Replication
For each partition, there exists one leader broker and follower brokers.
The config which controls how many such brokers (1 + N) exist is replication.factor. That is the total amount of times the data inside a single partition is replicated across the cluster.
The default and typical recommendation is three.
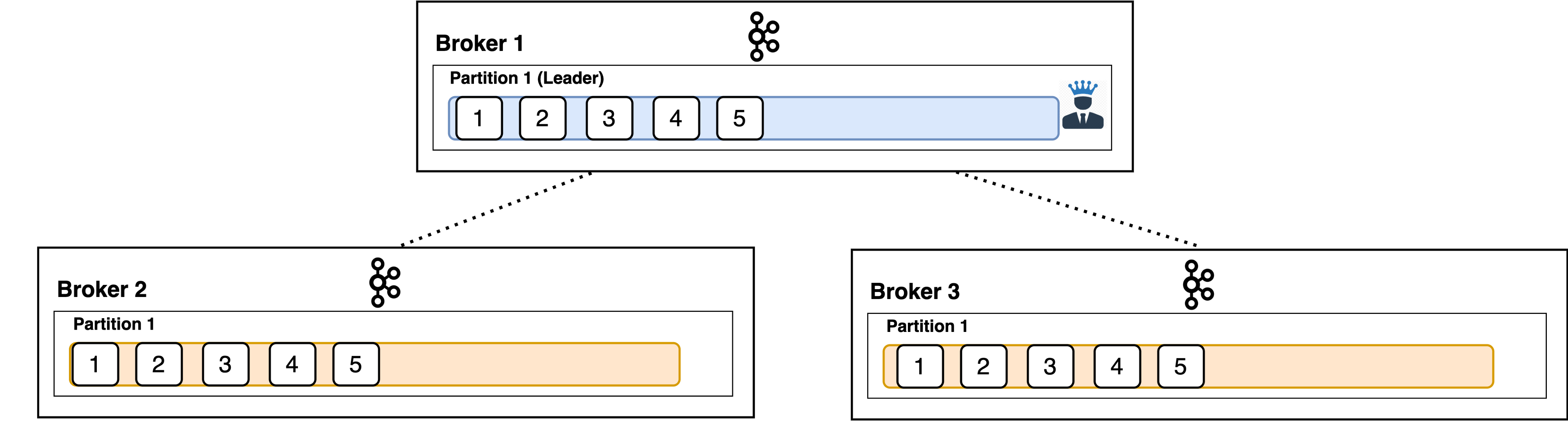
Producer clients only write to the leader broker’s followers asynchronously to replicate the data.
In-sync replicas
An in-sync replica (ISR) is a broker that has the latest data for a given partition. In other words, In-Sync Replicas are the replicated partitions that are in sync with their leader, i.e. those followers that have the same messages (or in sync) as the leader. It is not mandatory to have ISR equal to the number of replicas.
A leader is always an in-sync replica. A follower is an in-sync replica only if it has fully caught up to the partition it is following. In other words, it can not be behind on the latest records for a given partition.
If a follower broker falls, after 10 seconds it will be removed from the ISR. Likewise, if a follower slows down, perhaps a network-related issue or constrained server resources, then as soon as it has been lagging behind the leader for more than 10 seconds it is removed from the ISR.
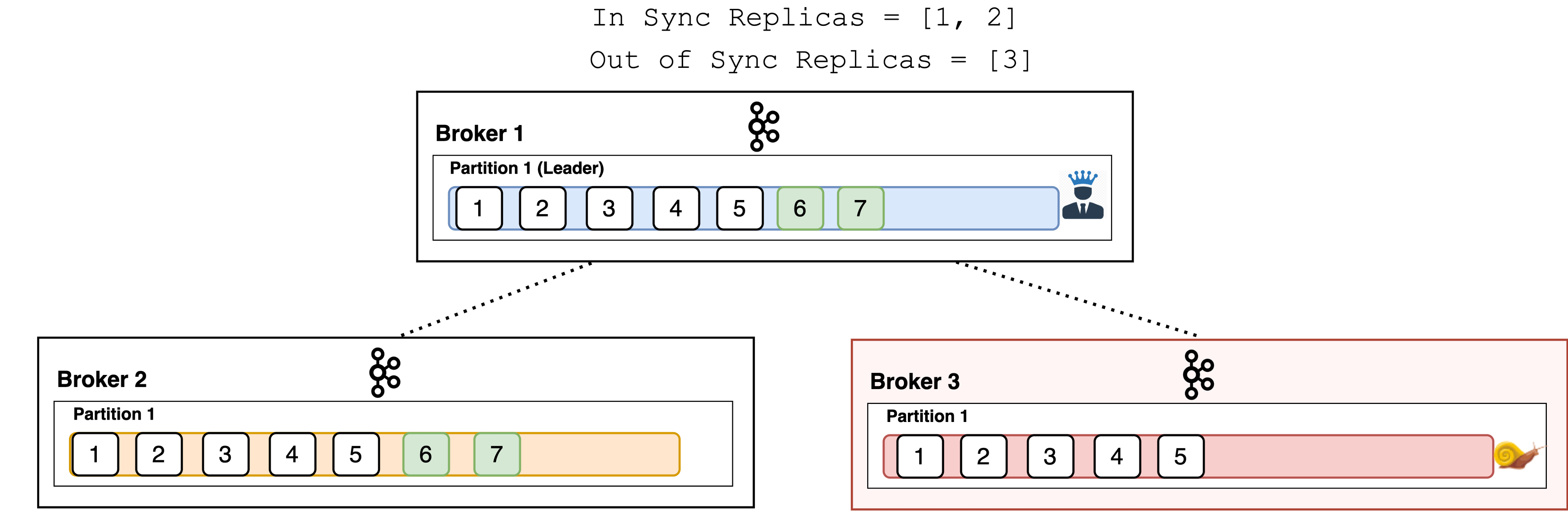
Instead of checking after 10 seconds you can configure this time period at: replica.lag.time.max.ms
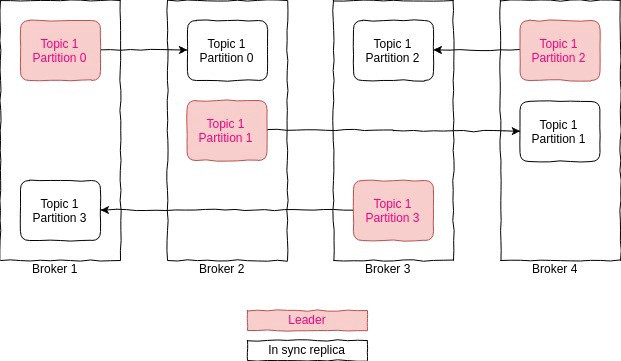
when we say a topic has a replication factor of 2 that means we will be having two copies of each of its partitions. Kafka considers that a record is committed when all replicas in the In-Sync Replica set (ISR) have confirmed that they have written the record to disk.
Acknowledgements (ACKS)
The acks setting is a client (producer) configuration. It denotes the number of brokers that must receive the record before we consider the write as successful. It supports three values are: 0, 1, and all.
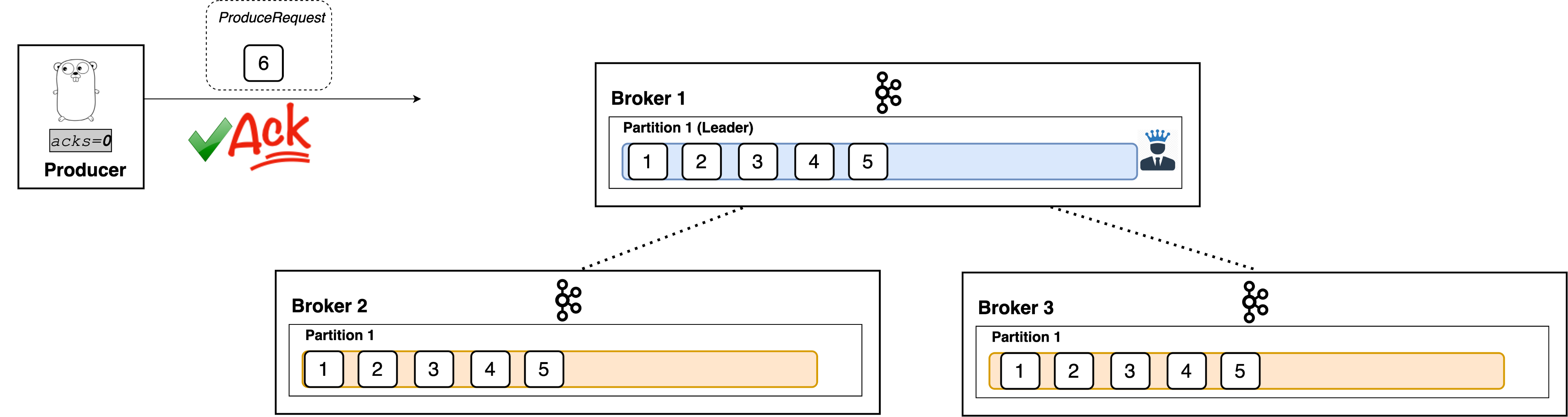
acks=0
With a value of 0, the producer won’t even wait for a response from the broker. It immediately considers the write successful the moment the record is sent out.
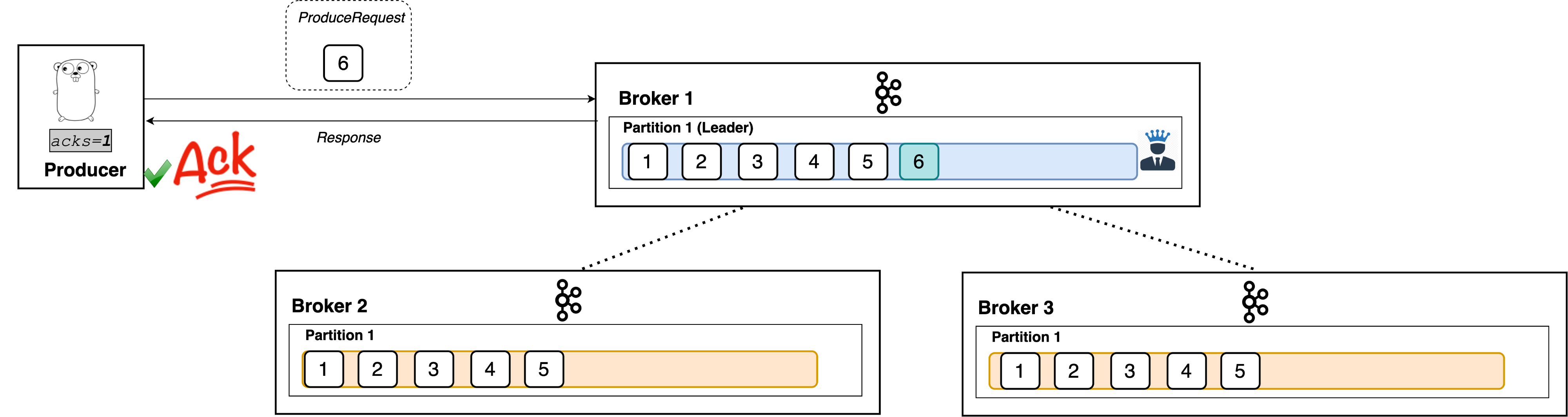
acks=1
With a setting of 1, the producer will consider the write successful when the leader receives the record. The leader broker will know to immediately respond the moment it receives the record and not wait any longer.
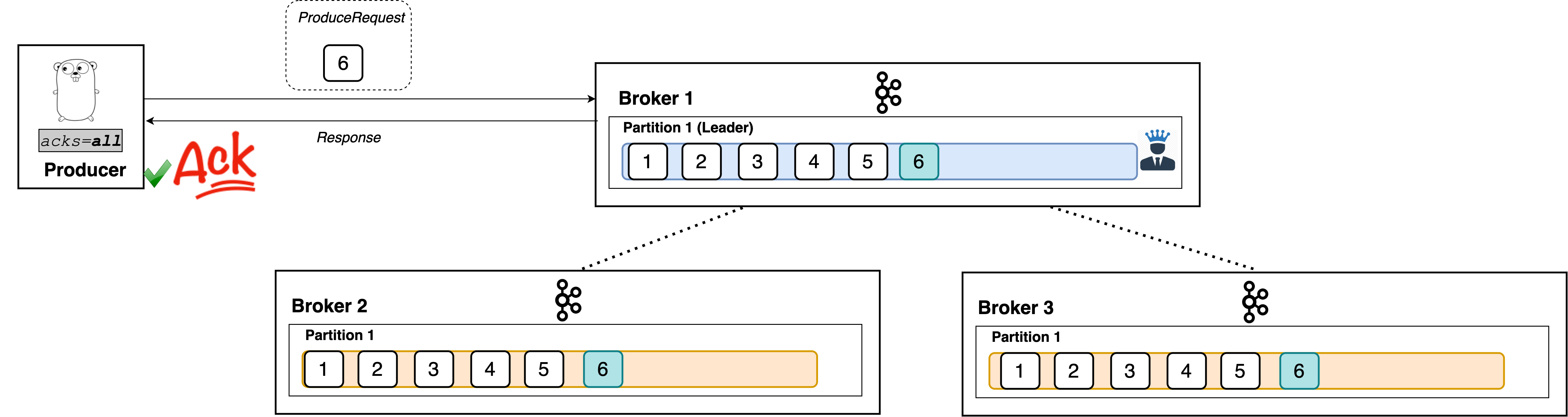
acks=all
When set to all, the producer will consider the write successful when all of the in-sync replicas receive the record. This is achieved by the leader broker being smart as to when it responds to the request it will send back a response once all the in-sync replicas receive the record themselves.
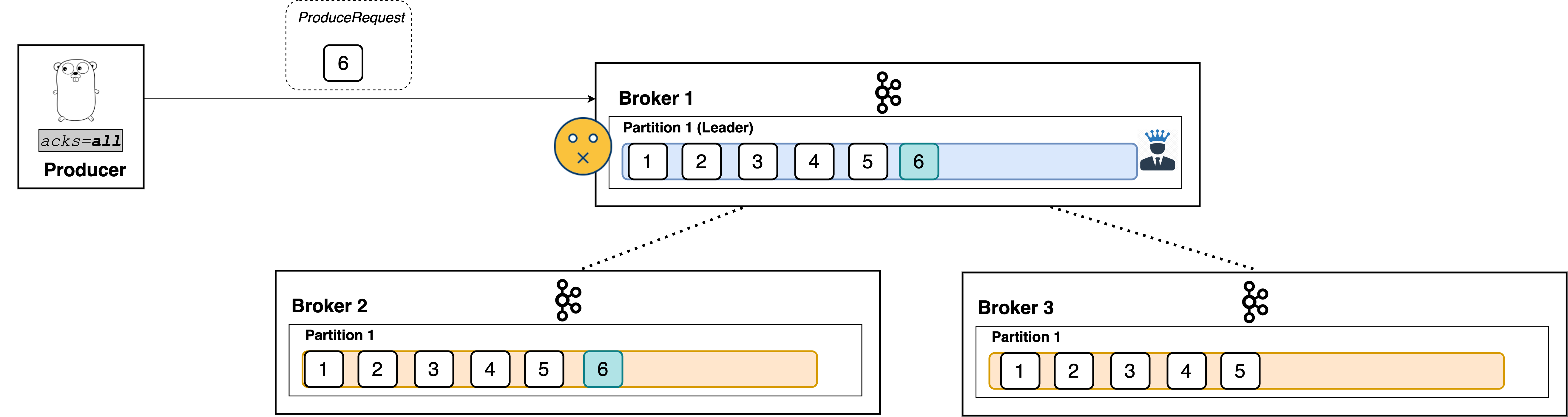
Like I said, the leader broker knows when to respond to a producer that uses acks=all.
Minimum In-Sync Replica
min.insync.replicas is a config on the broker that denotes the minimum number of in-sync replicas required to exist for a broker to allow acks=all requests. That is, all requests with acks=allwon’t be processed and receive an error response if the number of in-sync replicas is below the configured minimum amount. It acts as a sort of gatekeeper to ensure scenarios like the one described above can not happen.
If this minimum cannot be met, then the producer will raise an exception (either NotEnoughReplicas or NotEnoughReplicasAfterAppend).
As shown, min.insync.replicas=X allows acks=all requests to continue to work when at least x replicas of the partition are in sync. Here, we saw an example with two replicas.
But if we go below that value of in-sync replicas, the producer will start receiving exceptions.
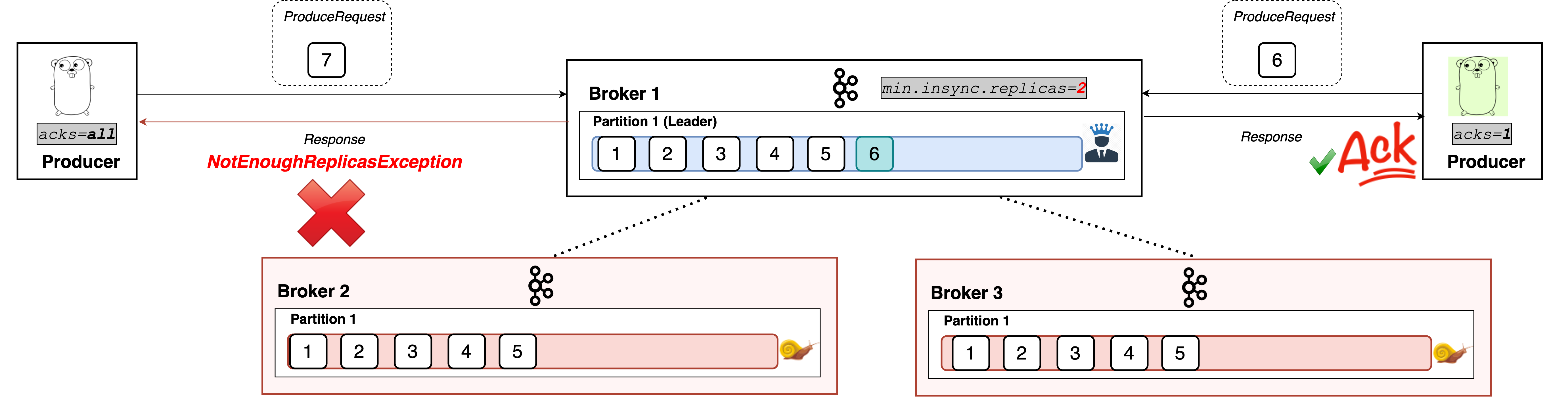
As you can see, producers with acks=all can’t write to the partition successfully during such a situation. Note, however, that producers with acks=0 or acks=1 continue to work just fine.
Caveat
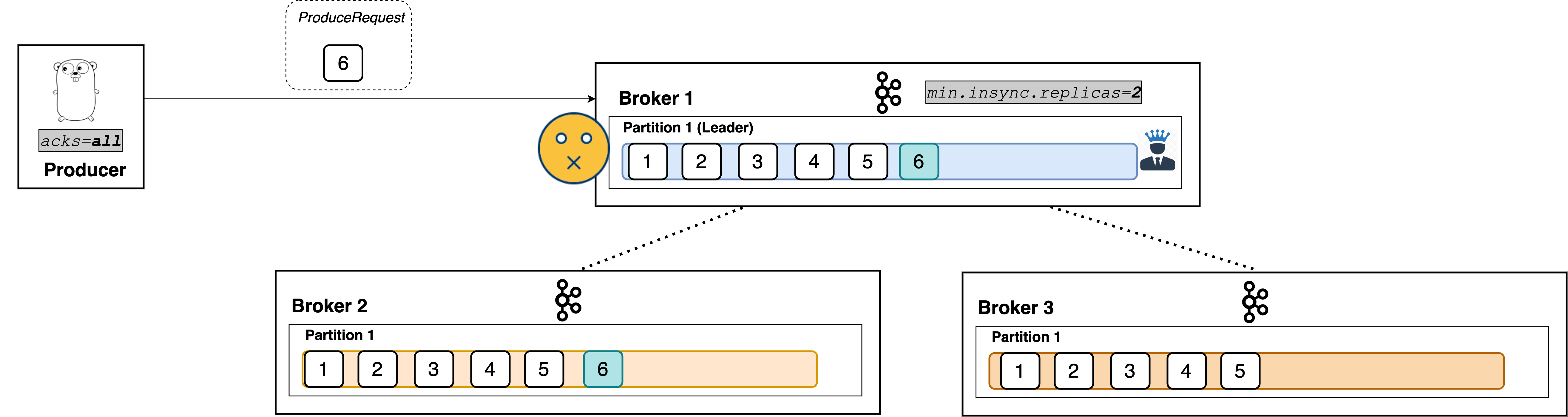
A common misconception is that min.insync.replicas denotes how many replicas need to receive the record in order for the leader to respond to the producer. That is not true: the config is the minimum number of in-sync replicas required to exist in order for the request to be processed.
That is, if there are three in-sync replicas and min.insync.replicas=2, the leader will respond only when all three replicas have the record.
Summary
To recap, acks and min.insync.replicas settings are what let you configure the preferred durability requirements for writes in your Kafka cluster.
acks=0the write is considered successful the moment the request is sent out. No need to wait for a response.acks=1the leader must receive the record and respond before the write is considered successful.acks=allall online in sync replicas must receive the write. If there are less thanmin.insync.replicasonline, then the write won’t be processed.


Comments are closed.