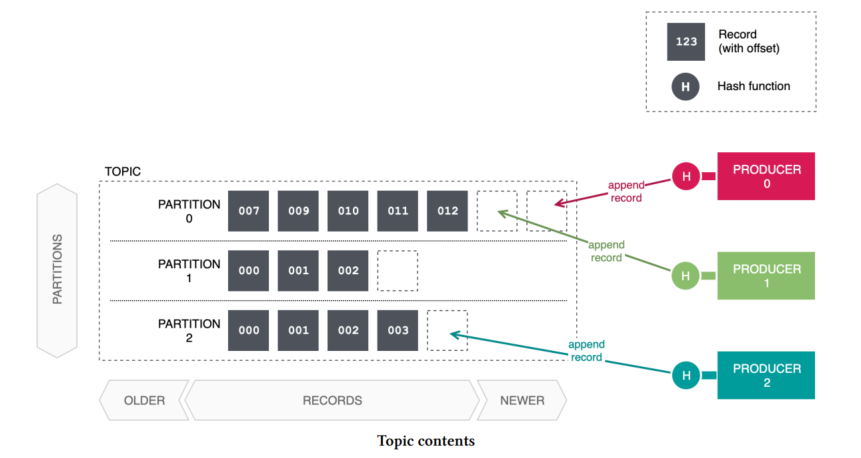
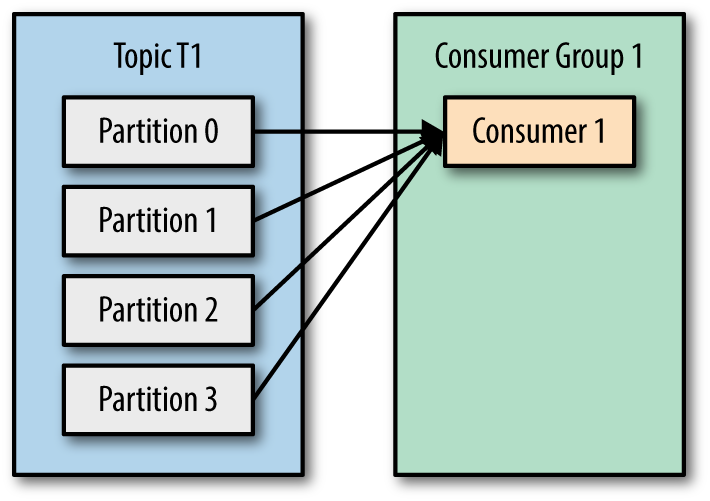
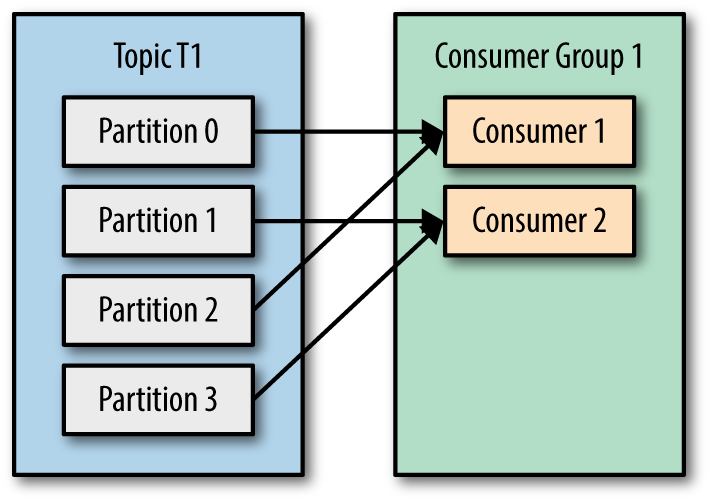
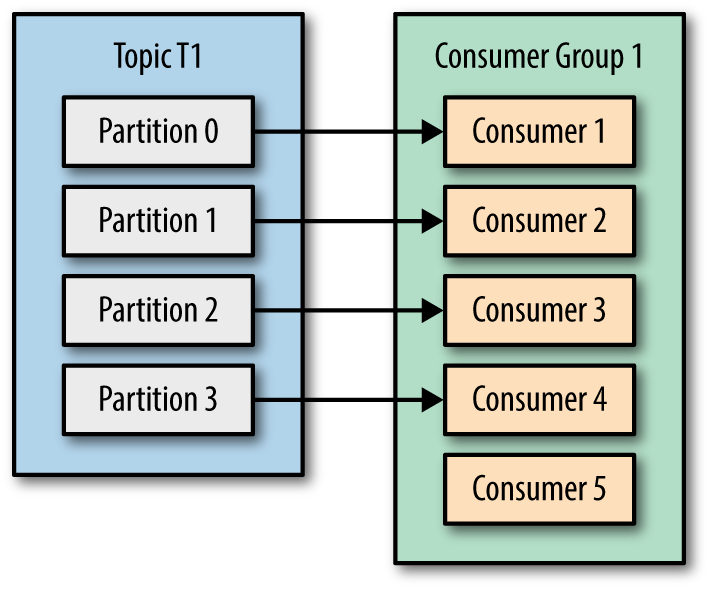
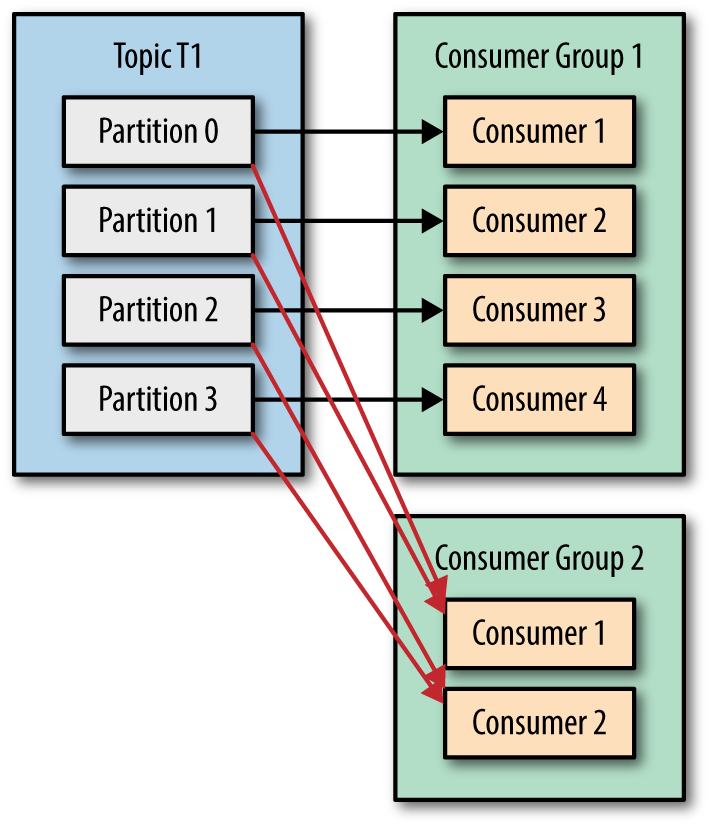
After you had read 2 articles about Kafka: What is Apache Kafka? and How to install Apache Kafka on Windows you can be confident to develop a Kafka application with Java by using Spring Boot framework.
Create Kafka application in Java
In this tutorial I will use IntelliJ IDEA to develop Kafka application, you can download IntelliJ at https://www.jetbrains.com/idea/.
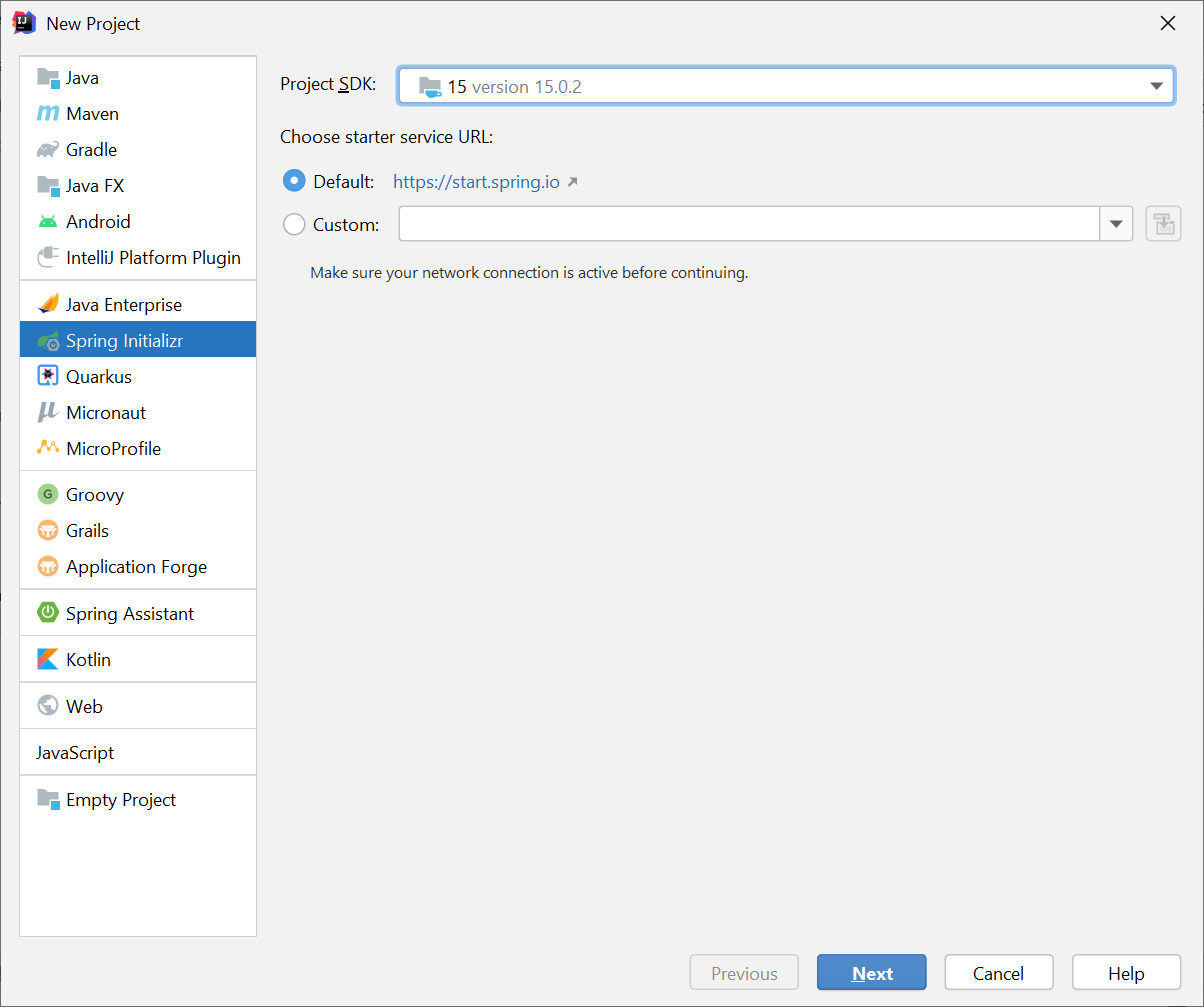
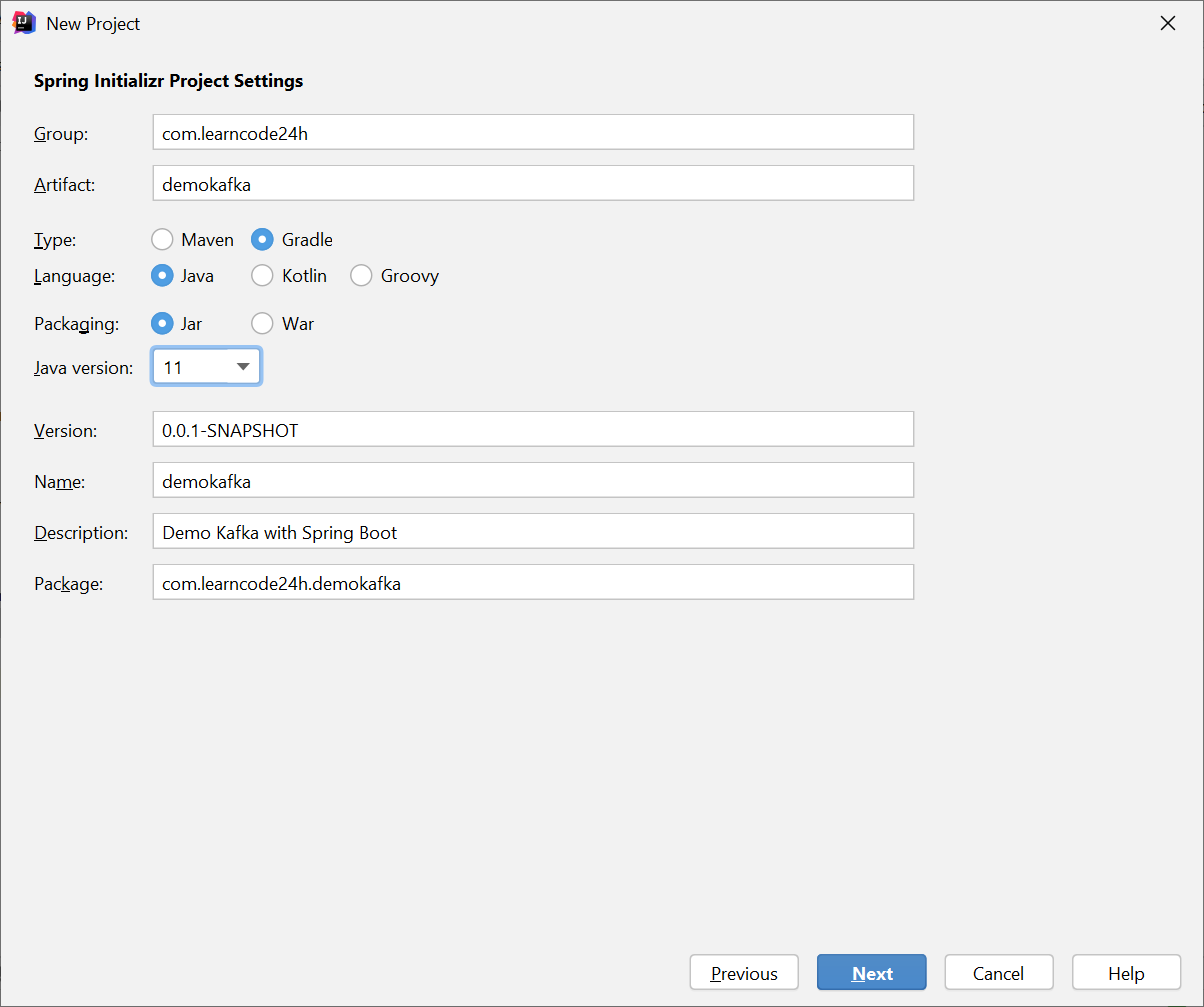
Step1: Create Spring Project and choose Gradle instead of Maven (you can also choose Maven if you like)
Open build.gradle and replace
org.springframework.boot:spring-boot-starter by org.springframework.boot:spring-boot-starter-web
build.gradle
plugins {
id 'org.springframework.boot' version '2.4.5'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id 'java'
}
group = 'com.learncode24h'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '11'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.kafka:spring-kafka'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.kafka:spring-kafka-test'
}
test {
useJUnitPlatform()
}
create config folder then create ProducerConfiguration.java
ProducerConfiguration.java
package com.learncode24h.demokafka.config;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class ProducerConfiguration {
private static final String KAFKA_BROKER = "localhost:9092";
@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigurations());
}
@Bean
public Map<String, Object> producerConfigurations() {
Map<String, Object> configurations = new HashMap<>();
configurations.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_BROKER);
configurations.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configurations.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return configurations;
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
This class creates a ProducerFactory which knows how to create producers based on the configurations you provided. You’re also specified to connect to your local Kafka broker and to serialize both the key and the values with String.
Then you need to declared a KafkaTemplate bean to do operations such as sending a message to a topic and efficiently hides under-the-hood details from you.
Next, we will create a KafkaController, you’ll access a url to send messages to Kafka broker. I will create KafkaController in controller package.
KafkaController.java
package com.learncode24h.demokafka.controller;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class KafkaController {
private KafkaTemplate<String, String> template;
public KafkaController(KafkaTemplate<String, String> template) {
this.template = template;
}
@GetMapping("/kafka/produce")
public void produce(@RequestParam String message) {
template.send("test", message);
}
}
Now let’s start Kafka ZooKeeper, Kafka server and a consumers to monitor Kafka application send messages to broker.
Start Kafka ZooKeeper
C:\kafka\config>zookeeper-server-start.bat zookeeper.properties
Start Kafka Broker
C:\kafka\config>kafka-server-start.bat server.properties
Create topic test
C:\kafka\config>kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Run Kafka project and you will see a created producer in log.
Start consumer
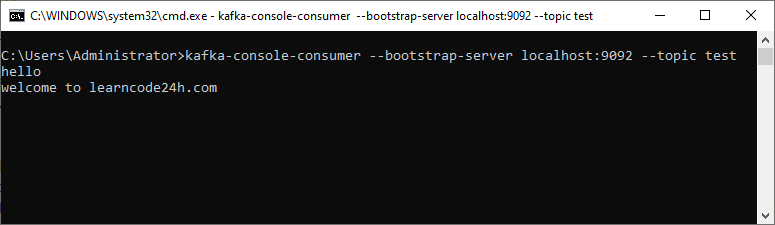
C:\kafka\config>kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
Open your web browser and access http://localhost:8080/kafka/produce?message=hello and http://localhost:8080/kafka/produce?message=welcome%20to%20learncode24h.com. After you hit enter, the created producer will send message “hello” and “welcome to learncode24h.com” to broker. Consumer subscribes topic test will print out these messages.
Create Kafka Consumer
Instead of listening message from terminal, we will implement consumer in Java. Create ConsumerConfiguration.java in config package
ConsumerConfiguration.java
package com.learncode24h.demokafka.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class ConsumerConfiguration {
private static final String KAFKA_BROKER = "localhost:9092";
private static final String GROUP_ID = "kafka-group";
@Bean
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigurations());
}
@Bean
public Map<String, Object> consumerConfigurations() {
Map<String, Object> configurations = new HashMap<>();
configurations.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_BROKER);
configurations.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configurations.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configurations.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return configurations;
}
@Bean
ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
The code above creates a factory and connects to your broker. It also configures your consumer to deserialize a String for both the key and the value, matching the producer configuration.
The Group ID is mandatory and used by Kafka to allow parallel data consumption. If you only have a consumer you can skip this param. The ConcurrentKafkaListenerContainerFactory bean allows your app to consume messages in more than one thread.
Now that your Java app is configured to find consumers inside your Kafka broker, let’s start listening to the messages sent to the topic. Create KafkaConsumer.java in consumer package
KafkaConsumer.java
package com.learncode24h.demokafka.consumer;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
@Component
public class KafkaConsumer {
private final List<String> messages = new ArrayList<>();
@KafkaListener(topics = "test", groupId = "kafka-group")
public void listen(String message) {
synchronized (messages) {
messages.add(message);
}
}
public List<String> getMessages() {
return messages;
}
}
This class is responsible for listening to changes in the testtopic. It does so by using the KafkaListener annotation. Every time a new message is sent from a producer to the topic, your app receives a message inside this class. It adds a message to the list of messages received and makes it available to other classes through the getMessages() method.
Next, let’s create an endpoint that displays a list of consumed messages. Go back to the KafkaController and add getMessage method.
KafkaController
package com.learncode24h.demokafka.controller;
import com.learncode24h.demokafka.consumer.KafkaConsumer;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class KafkaController {
private KafkaTemplate<String, String> template;
private KafkaConsumer kafkaConsumer;
public KafkaController(KafkaTemplate<String, String> template, KafkaConsumer kafkaConsumer) {
this.template = template;
this.kafkaConsumer = kafkaConsumer;
}
@GetMapping("/kafka/produce")
public void produce(@RequestParam String message) {
template.send("test", message);
}
@GetMapping("/kafka/messages")
public List<String> getMessages() {
return kafkaConsumer.getMessages();
}
}
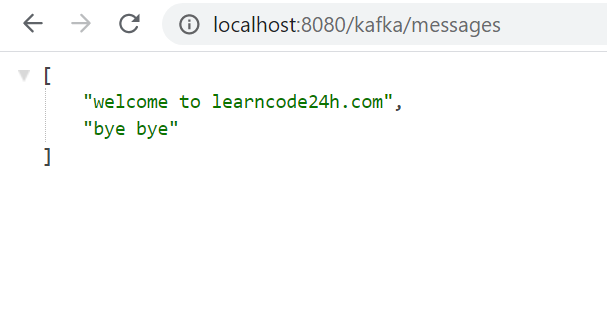
Now rebuild project, go to your browser then access http://localhost:8080/kafka/produce?message=welcome%20to%20learncode24h.com and http://localhost:8080/kafka/produce?message=bye%20bye
Open url http://localhost:8080/kafka/messages and you will see all messages.
Download source at https://github.com/learncode24h/demokafka